Object Detection using YOLO model
The real-time object detection is a key component of the autonomous driving system. It is widely used for problems like collision-avoidance, navigation, mapping. In this project, an object detection system is created using YOLO model[1].
It is assumed that a camera mounted on the car takes pictures of the road every few seconds while driving. The YOLO model takes pictures of road as input and outputs a list of bounding boxes along with the recognized classes, as shown in figure below.

Overview of YOLO
In this project, we use the “You Only Look Once” (YOLO) algorithm which achieves the high accuracy and real-time object detection. In particular, the predication is made by only one forward propagation through a Deep CNN.
The Encoding architecture for YOLO is shown as following:
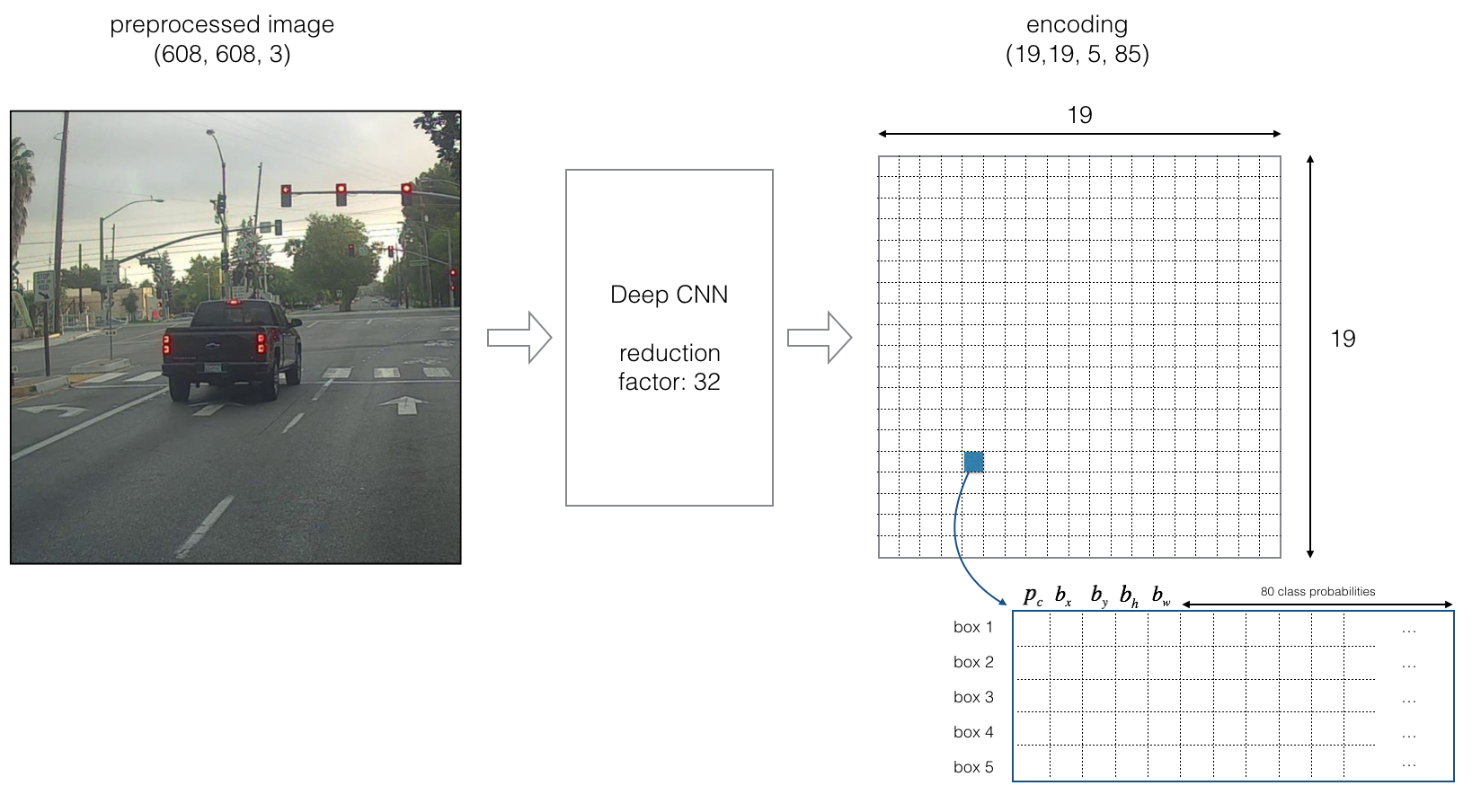
The input of the Deep CNN is image of size (608, 608, 3). The output of the network is an encoding of size (19, 19, 5, 85). More specifically, the input 608X608 image is partitioned by a 19X19 matrix in which each entry represents a part of region in the image. Each region is further represented by a 5X85 matrix, where each row indicates an anchor box with specific height/width ratio. Each anchor box contains information of the bounding box and classification, i.e., \((p_c, b_x, b_y, b_h, b_w, c_1, ..., c_{80})\) where \(p_c\) indicates the probability that the center of an object is in the bounding box. \(b_x, b_y\) refer to the coordinates of the center of bounding box in the current region and \(b_w, b_h\) represent the width and height of the bounding box. \(c_i\) indicates the probability that the object belongs to class i. Therefore, there are \(19\times19\times5=1805\) bounding boxes with probability \(\max_i \ p_c c_i\) for class \(\mathrm{argmax}_i \ p_c c_i\). This probability is called the score of box.
To reduce the number of boxes in the output, we can remove bounding box with score less than a threshold value.

As it is shown in figure above, some object is detected by multiple bounding boxes in different cells. To get more specific solution, we need to select one box when muliple overlapping boxes detect same object. The technique used here is called non-max suppression. The key steps are following:
- Remove boxes with score less than the threshold.
- Select the box with the highest score.
- Compute the intersection over union (IoU) with other overlapping boxes. Remove boxes that have high IoU.
- Go back to step 2 until no more boxes with lower score the current one.
Code Explanation
-
yolo_filter_boxes(box_confidence, boxes, box_class_probs, threshold): Filter boxes by thresholding on object and class confidence. Given the encoding (i.e.,box_confidence\(p_c\),boxes\(b_x, b_y, b_h, b_w\),box_class_probs\(c_1,...,c_{80}\)), return the boxes with probability greater thanthreshold. -
yolo_non_max_suppression(scores, boxes, classes, max_boxes, iou_threshold): Implement non-max suppression (step 2 to 4). -
yolo_eval(yolo_outputs, image_shape, max_boxes, score_threshold, iou_threshold): Convert the output of YOLO encoding which contains a large number of bounding boxes to a smaller number of the selected boxes after the filtering.
The classes of objects are defined in coco_classes.txt. The five anchor boxes are defined in yolo_anchors.txt. Due to the limitation of the hardware, we use a pre-trained YOLO model yolo.h5 which can be obtained from repository https://github.com/allanzelener/YAD2K.
The dataset used in this project is downloaded from BDD100K dataset.
To detect objects from the dataset, run python yolo_demo.py at the root of project directory.
Repository
References
-
You Only Look Once: Unified, Real-Time Object Detection
Joseph Redmon and Santosh Kumar Divvala and Ross B. Girshick and Ali Farhadi. CoRR 2015; abs/1506.02640. -
Convolutional Neural Networks: Detection Algorithm
Coursera, https://www.coursera.org/learn/convolutional-neural-networks.